SurgTEMP: Temporal-Aware Surgical Video Question Answering
with Text-guided Visual Memory
Abstract
Surgical procedures are inherently complex and risky, requiring extensive expertise and constant focus to well navigate evolving intraoperative scenes. Computer-assisted systems such as surgical visual question answering (VQA) offer promises for education and intraoperative support.
Current surgical VQA research largely focuses on static frame analysis, overlooking rich temporal semantics. Surgical video question answering is further challenged by low visual contrast, its highly knowledge-driven nature, diverse analytical needs spanning scattered temporal windows, and the hierarchy from basic perception to high-level intraoperative assessment.
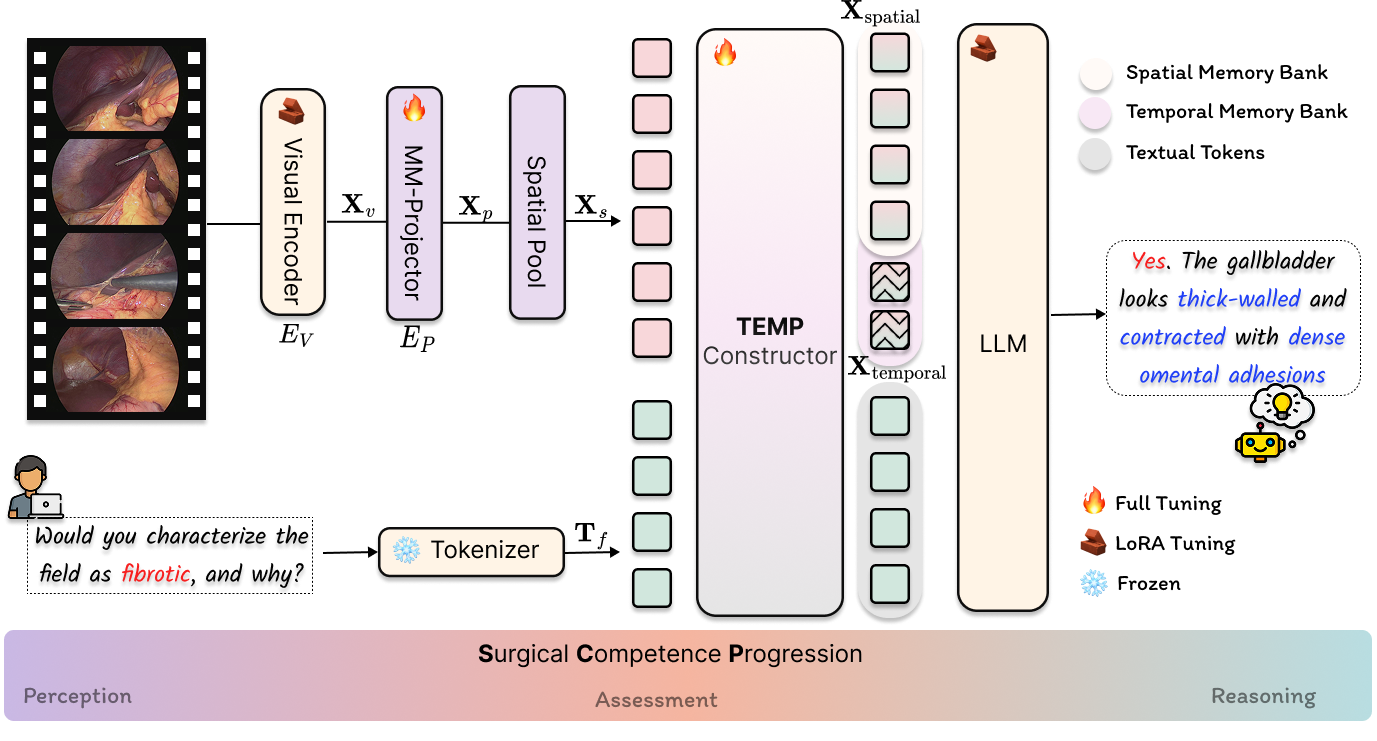
To address these challenges, we propose SurgTEMP, a multimodal LLM framework featuring (i) a query-guided token selection module that builds hierarchical visual memory (spatial and temporal memory banks) and (ii) a Surgical Competency Progression (SCP) training scheme. Together, these components enable effective modeling of variable-length surgical videos while preserving procedure-relevant cues and temporal coherence, and better support diverse downstream assessment tasks.
To support model development, we introduce CholeVidQA-32K, a surgical video question answering dataset comprising 32K open-ended QA pairs and 3,855 video segments (~128 h total) from laparoscopic cholecystectomy. The dataset is organized into a three-level hierarchy — Perception, Assessment, and Reasoning — spanning 11 tasks from instrument/action/anatomy perception to Critical View of Safety (CVS), intraoperative difficulty, skill proficiency, and adverse event assessment.
In comprehensive evaluations against state-of-the-art open-source multimodal and video LLMs (fine-tuned and zero-shot), SurgTEMP achieves substantial performance improvements, advancing the state of video-based surgical VQA.
Highlights
SurgTEMP Model
Multimodal LLM for surgical video VQA across 11 clinically relevant tasks, combining spatial and temporal memory banks guided by the text query.
TEMP Constructor
Text-guided attention selects the most query-relevant frames and patches, building a hierarchical spatial–temporal visual memory pyramid.
SCP Training
Surgical Competency Progression progressively builds perception, assessment, and reasoning capabilities — mirroring clinical training.
CholeVidQA-32K
32K open-ended QA pairs from 3,855 laparoscopic cholecystectomy segments (~128 h) spanning a 3-level task hierarchy.
Text-guided Memory Pyramid (TEMP)
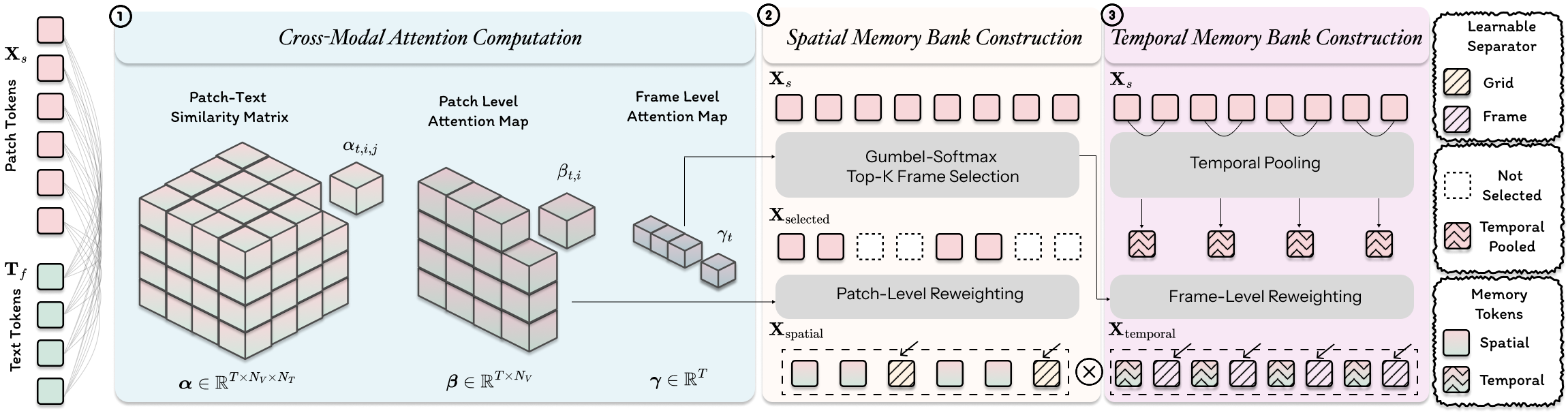
The TExt-guided Memory Pyramid (TEMP) constructor computes patch-text and frame-text similarity via cross-modal attention, then uses differentiable frame selection (Gumbel-Softmax) to build a spatial memory bank of the most query-relevant patches and a temporal memory bank of reweighted frame representations.
CholeVidQA-32K Dataset
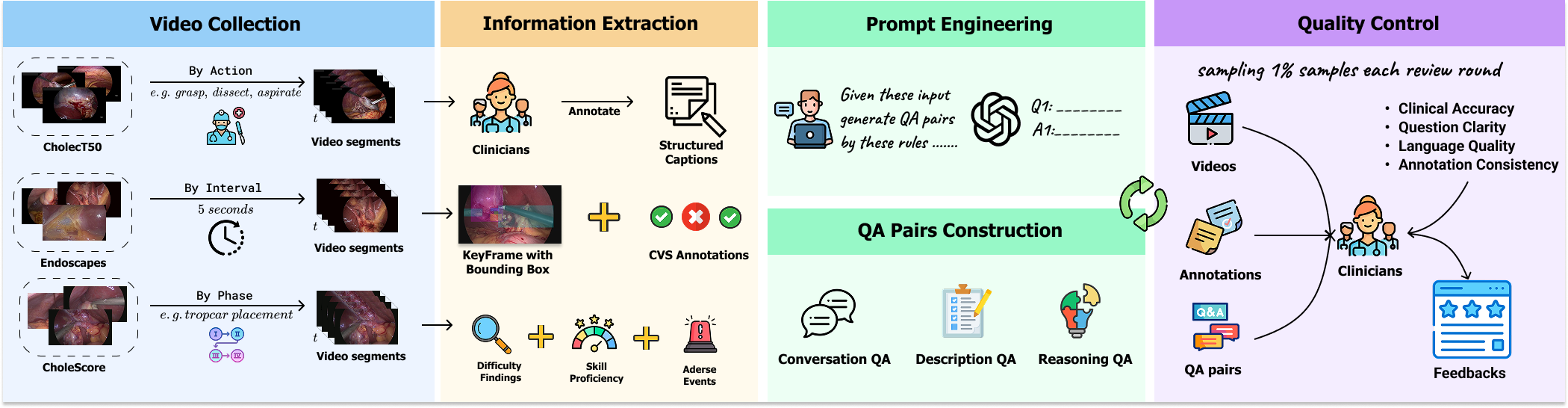
Dataset Curation Pipeline. QA pairs are generated through a multi-stage pipeline combining clinician annotations from CholecT50, Endoscapes, and CholeScore with structured LLM-based QA generation and clinical validation.
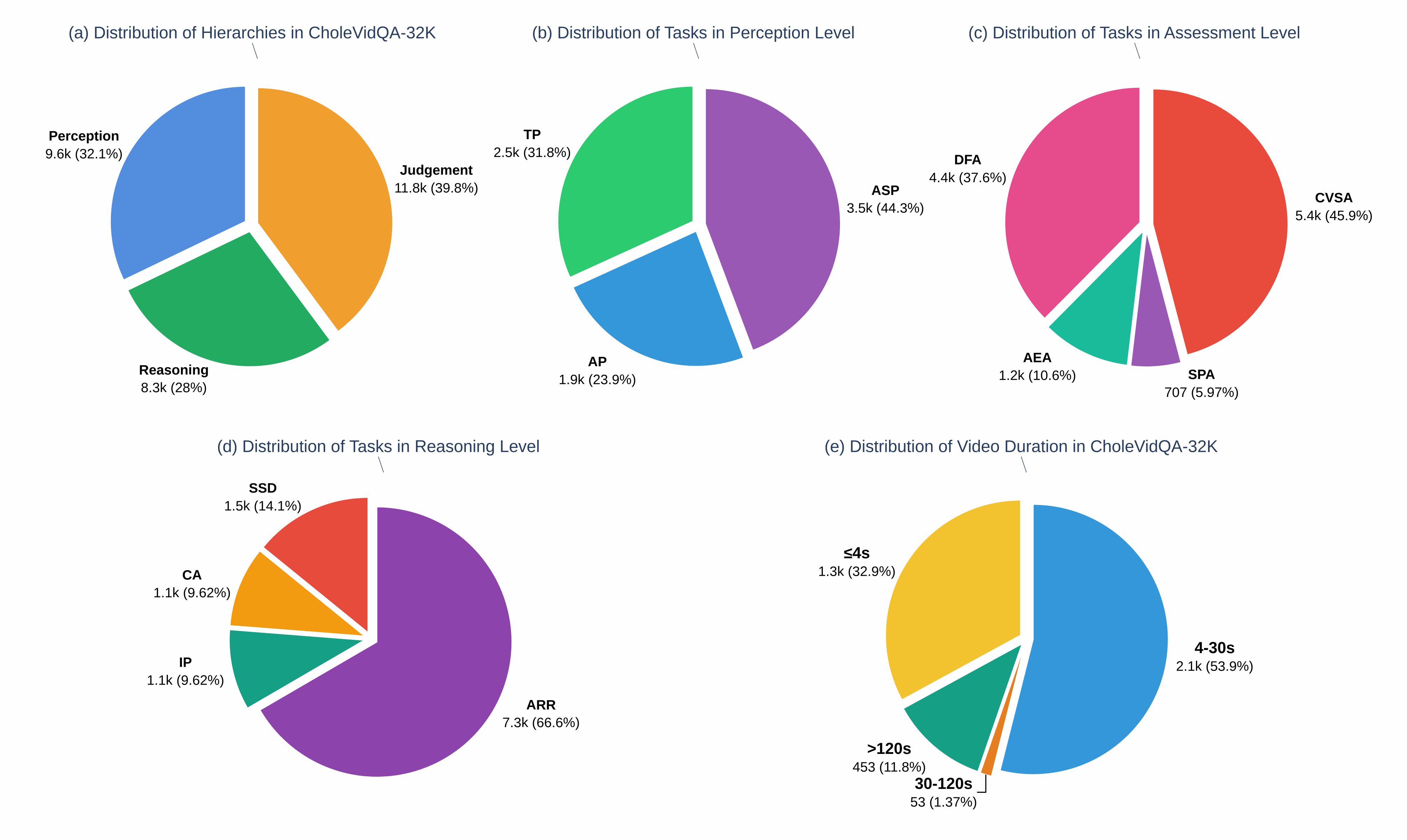
Dataset Statistics. Composition breakdown by hierarchy level, task type, and video segment duration — 32K QA pairs from 3,855 segments across CholecT50, Endoscapes, and CholeScore.

Sample QA Pairs. Examples from all three hierarchy levels — Perception, Assessment, and Reasoning — illustrating the diversity of question types and clinical reasoning required.
Three-Tier Evaluation Framework
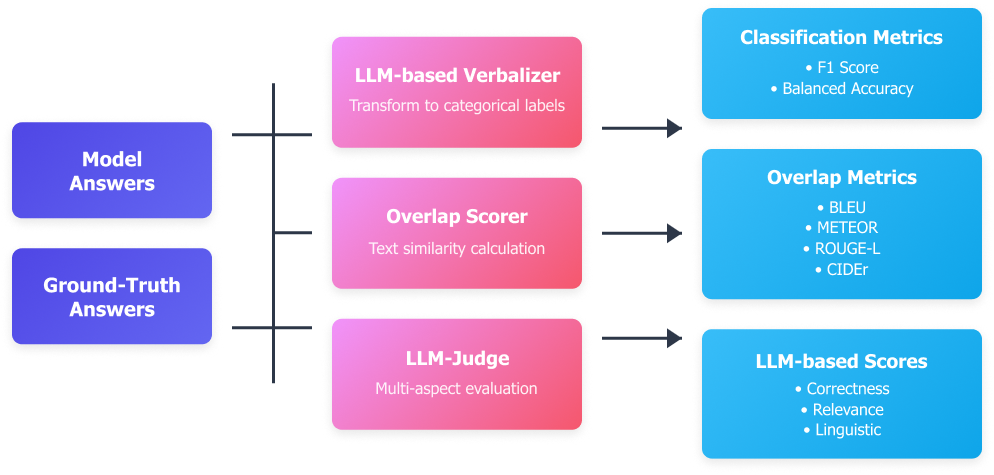
Evaluation combines (1) an LLM-based verbalizer for categorical F1 & balanced accuracy, (2) text overlap metrics (BLEU, METEOR, ROUGE-L, CIDEr), and (3) an LLM judge scoring correctness, relevance, and linguistic quality. Multi-judge agreement (Kendall's W = 0.852) confirms evaluation robustness.
Quantitative Results
Overall performance on the CholeVidQA-32K test set across GPT Scores (Correctness, Relevance, Linguistic Quality), Overlap Metrics (BLEU, METEOR, ROUGE-L, CIDEr), and Classification Metrics (balanced Accuracy and F1-score, with answer rates). SurgTEMP attains the best fine-tuned score on every single metric.
| Models | GPT Scores | Overlap Metrics | Classification Metrics | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| CR | RL | LG | BLEU | METEOR | ROUGE-L | CIDEr | bAcc | F1-score | |||
| Score | Rate | Score | Rate | ||||||||
| Open-source Zero-shot | |||||||||||
| mPLUG-Owl3 | 32.06 | 45.00 | 43.09 | 5.57 | 23.81 | 23.12 | 6.40 | 32.29 | 95 | 15.00 | 97 |
| InternVideo2.5 | 16.28 | 19.38 | 16.56 | 2.93 | 8.87 | 9.78 | 4.67 | 25.71 | 91 | 1.24 | 7 |
| LongVA | 25.81 | 34.90 | 34.68 | 1.91 | 21.61 | 14.21 | 0.61 | 5.07 | 9 | 22.46 | 56 |
| LLaVA-Video | 33.29 | 41.07 | 38.72 | 3.76 | 21.39 | 17.20 | 4.01 | 27.34 | 49 | 12.56 | 65 |
| VideoGPT+ | 36.65 | 48.32 | 46.61 | 3.83 | 21.96 | 22.68 | 14.19 | 40.20 | 68 | 25.13 | 78 |
| Fine-tuned | |||||||||||
| VideoGPT+-ft | 64.06 | 73.58 | 71.63 | 14.62 | 33.29 | 31.87 | 42.33 | 52.37 | 95 | 49.30 | 82 |
| LLaVA-Video-ft | 60.05 | 67.30 | 65.56 | 14.67 | 32.44 | 31.41 | 40.85 | 51.31 | 88 | 44.20 | 63 |
| SurgTEMP (Ours) | 71.62 | 81.65 | 79.12 | 15.29 | 36.28 | 34.90 | 42.53 | 56.53 | 100 | 52.33 | 91 |
For classification metrics, Score is the metric value on answered samples and Rate (%) is the answer rate. ■ Best among Open-source Zero-shot · ■ Best among Fine-tuned.
Qualitative Results

Reasoning — Comprehensive Assessment & Action Rationale. SurgTEMP generates multi-dimensional safety assessments and explains the rationale behind surgical actions.

Reasoning — Intraoperative Planning. The model provides scenario-based procedural guidance grounded in observed anatomy and tool use.
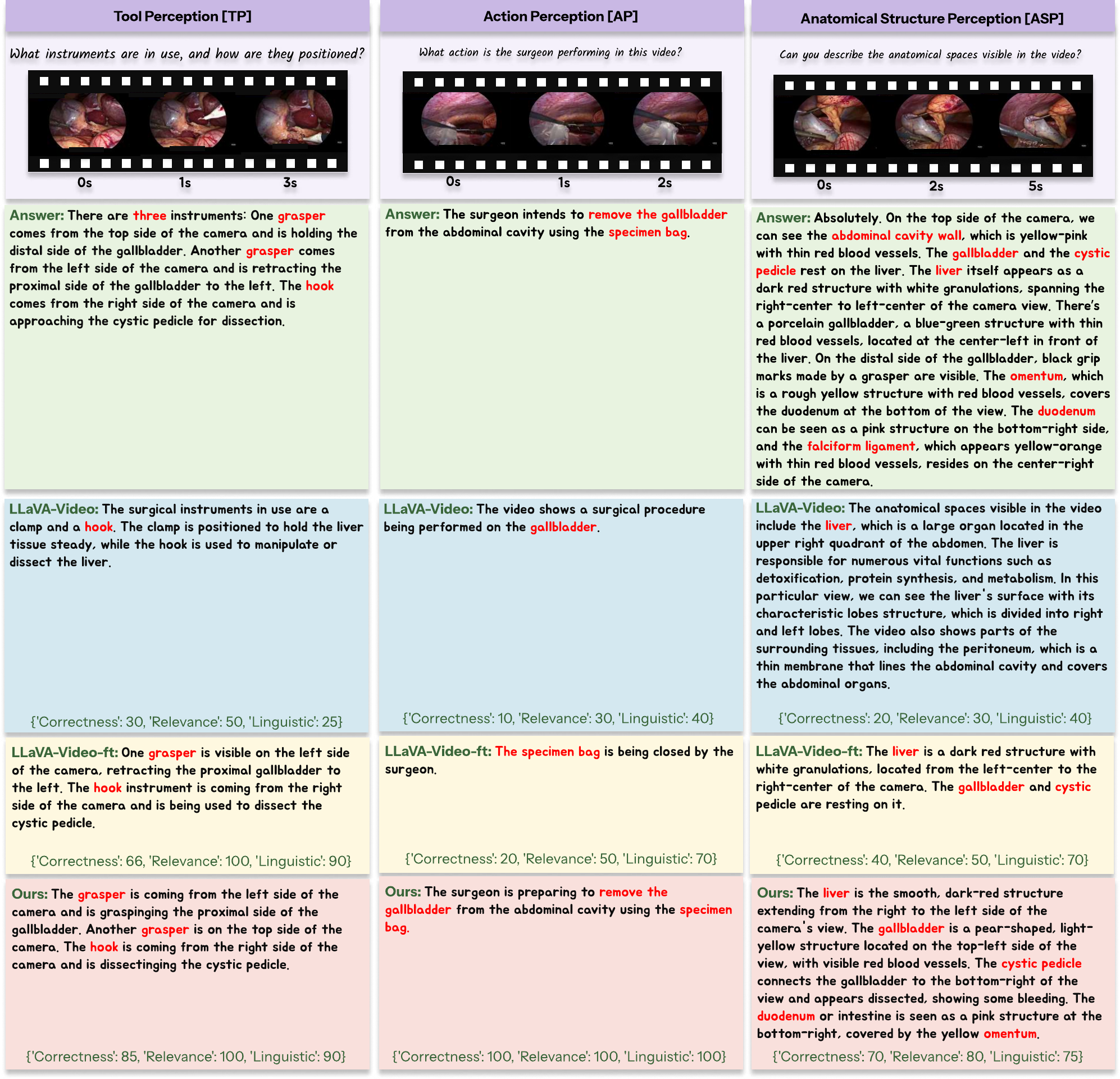
Perception — Tools, Actions & Anatomy. Fine-grained identification of surgical instruments, actions, and anatomical structures with clinical context.

Assessment — CVS, Difficulty & Skills. SurgTEMP accurately evaluates Critical View of Safety, intraoperative difficulty findings, and surgeon skill proficiency.
Acknowledgement
This work was funded by the European Union (ERC, CompSURG, 101088553) and French state funds managed by the ANR under Grants ANR-10-IAHU-02, ANR-23-IACL-0004, ANR-10-IDEX-0002, and ANR-20-SFRI-0012, with HPC resources provided by CAMMA, IHU Strasbourg, and Unistra Mesocentre.
License
The dataset, code, and model weights released with this work are licensed under Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0) .
You are free to share and adapt the material for non-commercial purposes, provided you give appropriate credit to the original authors and distribute any derivatives under the same license.
BibTeX
@misc{li2026surgtemptemporalawaresurgicalvideo,
title={SurgTEMP: Temporal-Aware Surgical Video Question Answering with Text-guided Visual Memory for Laparoscopic Cholecystectomy},
author={Shi Li and Vinkle Srivastav and Nicolas Chanel and Saurav Sharma and Nabani Banik and Lorenzo Arboit and Kun Yuan and Pietro Mascagni and Nicolas Padoy},
year={2026},
eprint={2603.29962},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2603.29962},
}